In this project for a client i used the twitter api and a python twitter library to search for all the tweets for a search term within a certain geographical distance. The downloader of tweets has been designed as a cron job which queries twitter for each search term, retrieves all the latest tweets available for that search term and stores the tweets found temporarily as physical files.
The downloader used oauth and python twitter library to connect to twitter to query over REST api to get JSON results back for the search term. In order to ensure that the tweets returned back contained location information this project used an initial position and search term and used twitter geo location search api. For twitter api the project used TwitterSearch library for python. The downloader has been designed to retry after few minutes for each search term to get around the problem of exhasuting twitter search api limit. This search is done daily to get any tweets every day for same search term not already stored before.
Once all the tweets for every search term is stored on disk then these files are processed to filter out the tweets which are too far in terms of location and then these data processing. Once the data is cleaned then for each tweet Natural Language Toolkit(nltk) for python is used to tokenize the tweets and assign each tweet a sentiment score based on a dictionary for ranking based on different attributes of the tweet.
After the data is processed and each tweet is assigned a score it is saved into NoSQL database like MongoDB. Finally, a small web service is written in python to get all tweets in the database from MongoDB and bundled into a json file and sent to the client side. On client side google map api plus a library for grouping multiple tweets in single location is used to display all tweets along with color used to represent the sentiment of the tweet.
The google map also has google map search integrated to focus on a location and view tweets only on that location.

All the tweets within the current view grouped by location.
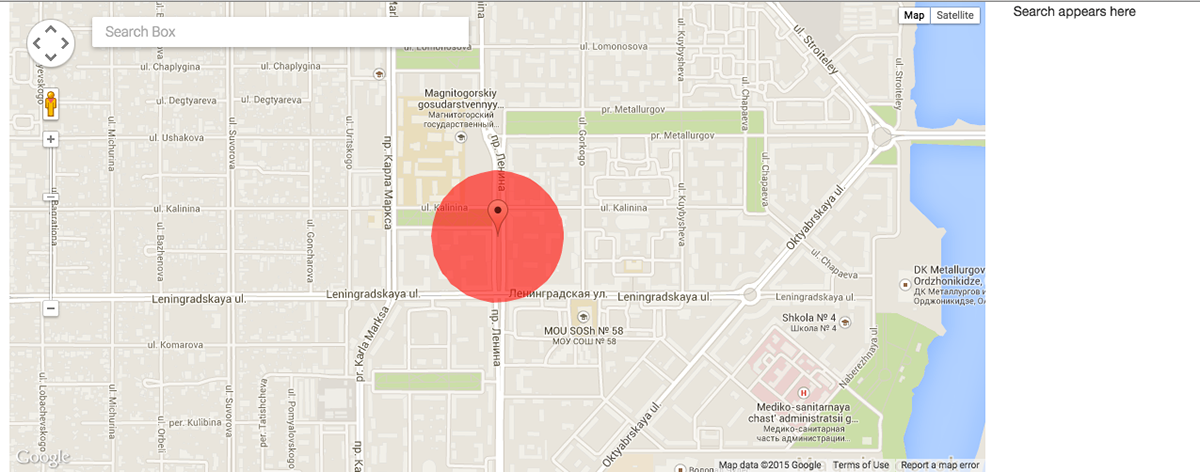
Zooming in to a location shows the tweet and it's color represents the sentiment of the view. Green circles show good score and red circles bad score based on sentiment of the tweet.

