MODELO DE REGRESION LINEAL MULTIPLE PARA DETERMINAR EL PERFIL DE LOS ASPIRANTES AL PUESTO DE "DATA ANALYST" Y "BUSINESS INTELLIGENCE"
INGENIERO MATEMÁTICO JOSÉ RODRIGO NERI LOZANO
SOBRE EL PROYECTO
En la primer etapa del proyecto (EDA): https://www.behance.net/gallery/195874867/EDA-PERFIL-PARA-DATA-ANALYST-Y-BUSINESS-INTELLIGENCE se preparo el dataset para la realizacion de este proyecto.
Para el desarrollo se emplearan las teorias estadisticas que nos permiten cuantificar la realcion lineal que existe entre dos variables o mas variables.
Para aplicar estas teorias es necesario verificar que los datos cumplen con ciertas condiciones.
ANALISIS DE NORMALIDAD
Presentemos como se comporta la distribucion para tener una primer intuicion de si tenemos relacion entre las variables.


Verifiquemos graficamente si los datos se distribuyen normalmente

Realicemos algunos test para ver numericamente como es la dispercion de los datos.

ANALISIS DE ASIMETRIA Y CURTOSIS
(-1 < V < 1) DESVIACION LIGERA
(-2 < V < 2) DESVIACION PERO NO ES EXTREMA
(-3 < V < 3) NO HAY NORMALIDAD
PARA LOS TEST DE SHAPIRO Y D'ANGOSTINO SE RECHAZA HIPOTESIS NULA: LOS DATOS SE DISTRIBUYEN CON NORMALIDAD PARA UN P-VALUE BAJO
Apoyandonos del grafico Q-Q y de los test que realizamos podemos rechazar normalidad para ambas variables.
ANALISIS DE HOMOCEDASTICIDAD


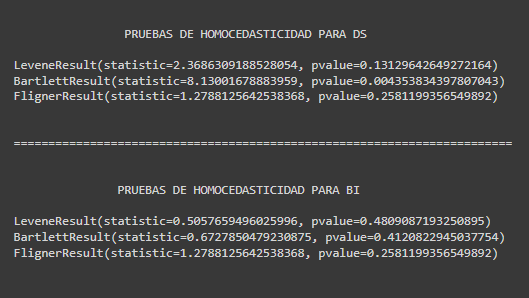
Dado que se rechazo normalidad en la seccion anterior tomaremos mas relevancia en las pruebas de bartlett ya que esta prueba se enfoca en analisis no parametricos.
Este test nos indica que no hay homocedasticidad lo cual ya se presentaba en los graficos de violin.
Dadas las condiciones de los datos se realizara la regresion utilizando la correlacion de spearman ya que esta se enfoca en pruebas no parametricas. El analisis se realizara de forma ilustrativa bajo algunas reservas las cuales seran mencionadas en las concluciones ya que se encuentran algunas condiciones "no idoneas" en los datos.
MODELO DE REGRESION LINEAL MULTIPLE
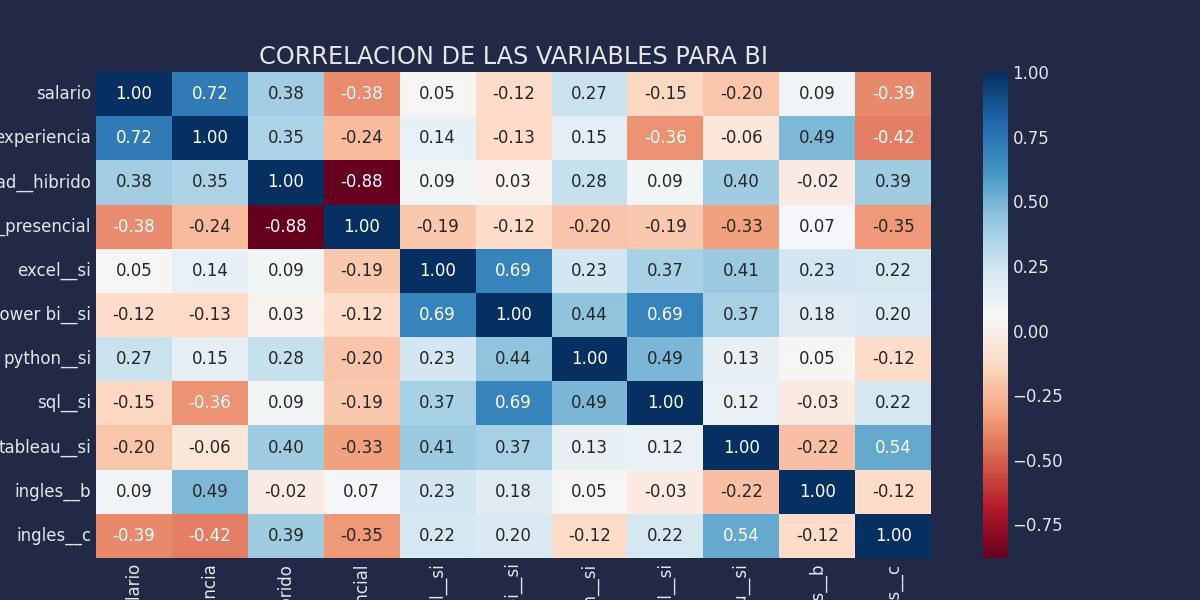
Creamos una matriz que muestre la correlacion careando vareable por vareable


Para un mejor analisis de las correlaciones entre varables realizamos un headmap para cada matriz

Imprimimos los estadisticos y variables mas importantes del modelo de regresion


Finalmente observamos cuales son los coeficientes de cada variable para determinar el salario de un postulante segun sus habilidades particculares


CONCLUSIONES:
En primer lugar mencionemos las deficiencias del data set:
1. Sobre el tamaño:
la muestra que se tiene es muy pequeña debido a que en la mayor parte de las publicaciones de empleo no es presentado el salario ni la experiencia, para el salario es inprecindible que los registros contengan este valor ya que es la variable explicativa, despues de las depuraciones quedaron 25 registros para ds y 19 registros para bi ( en estos modelos predictivos es recomendable contar con almenos de 10 a 20 veces la cantidad de variables explicativas).
2.Sobre los registros:
Para los registros de "conocimientos computacionales" y "habilidades blandas" el registro que se tiene es "si" en caso de que el empleador ESPECIFIQUE QUE SE REQUIERE DICHO CONOCIMIENTO y "unknown" en caso de que NO SE ESPECIFIQUE QUE SE REQUIERE DICHO CONOCIMIENTO, la situacion aqui es que en algunos casos los empleadores omiten dicha especificacion tomando en asumiendo que se cuenta con el conocimiento y no por que no se requiera, esto se ve reflejado en los coeficientes para algunas de estas variables en las que por el valor que toma podemos atribuirlo a que la mayor cantidad de registros para estas variables pertenecen a la subcategoria "unknow" y en los casos que se especifica como "si" en su mayoria es en empleos con salarios "cerca de la media" lo que "arrastra" dicho coeficiente al grado de ponerlo en valores negativos, de lo que podriamos determinar que en los empleos menor remunerados economicamente son en los que mas especificaciones tecnicas se presentan.
Conclusiones finales:
Para el caso de la modalidad puede cobrar sentido el echo de que en los trabajos que no sea requerido acudir a un centro laboral se remunere con menor salario frente a los que si es requerido.
En cuanto al intercepto dada la media que se tenia podemos conciderar que toma un valor no tan alejado de la realidad, esto conciderando lo antes mencionado.
Finalmente podemos decir que se tuvo un "mejor modelo" para el caso de los empleos del area bi, esto por lo reflejado en los coeficientes y en la comparacion del valor de la R ajustada la cual nos dio para ds: 35.5% mientras que para bi: 56.5%
